# 🐉 2.1. Case study: STAR WARS corpus
When querying search engines, the user can associate several keywords to clearly define the exploration conditions:
- Boolean parameters (AND/OR/NOT) and quotation marks,
- Publication date (publicationDate:[2010 TO *]),
- Authors (author.name:*)
- The presence of an abstract (abstract:*)
- PDF image elimination (qualityIndicators.pdfWordCount:[500 TO *])
These formulations are not recognized by all databases. This depends on the degree of metadata enrichment. ISTEX is one of the most extensive metadata repositories. You can find all the functions on the ISTEX demonstrator (a pedagogical tool thanks to the advanced search function).
The GarganText mapping tool analyzes the terms in a document corpus and offers the user several visualization models that can be modified. When starting a documentary exploration project, an initial search on a multi-disciplinary database such as HAL or ISTEX enables you to mark out the main axes (clusters) of the documentary study.
Research problem: what influence does the "Star Wars" universe have on modern popular culture among young people?
We created an initial map using Gargantext on the ISTEX corpus, indicating "Star Wars" as a keyword to explore the wider environment of the research topic.
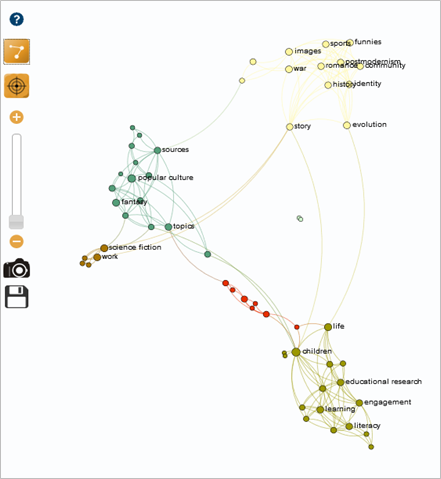
The result is the following map, organized into 5 colored clusters, each representing a thematic grouping: a set of related terms in the "Star Wars" universe (context, synonym, etc.).
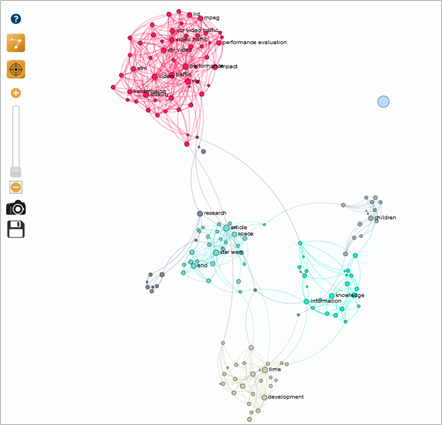
The query is not fine enough to provide relevant, usable results on the research topic. Nevertheless, this first query enables us to define the main themes and target several keywords to improve the initial query.
Key terms vs. keywords
- Pivotal terms: The main terms of our search already identified. For example, Star Wars, popular culture, youth, etc.
- Keywords: words linked to our pivotal terms, which are generally found in the same cluster and provide information on the nature of the link.
## Cluster study
At this stage, the aim is to define the theme of each cluster and determine which keywords might be related to the subject under study.
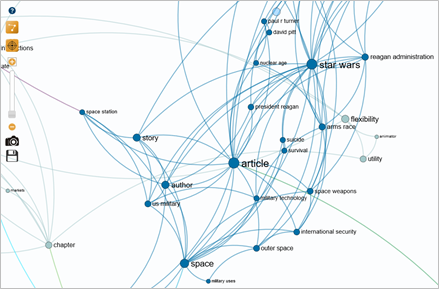
The dark blue cluster contains the pivotal term "Star Wars" in its linking points. This cluster essentially reveals keywords on the themes of space, the military, politics, etc. This cluster is far removed from our research topic.
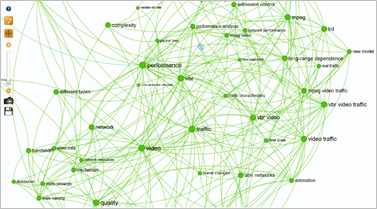
The green cluster groups together technical terms relating to video, editing, special effects and data flow. There are no pivotal terms to be found here, and it doesn't enhance our angle of analysis.
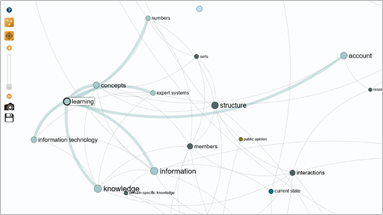
The light blue cluster reveals the structuring of the "Star Wars" universe, highlighting learning, knowledge, information, concepts and so on. This cluster is particularly interesting since the term "learning" can refer to the transmission of knowledge to a young audience.
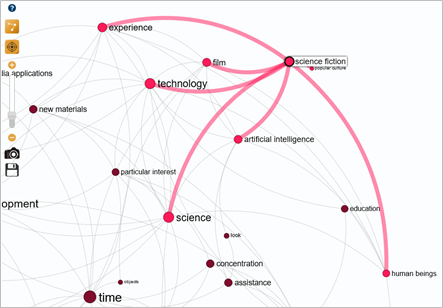
The red cluster refers to technological development, temporality and science fiction. Focusing on "science fiction", the pivotal term "popular culture" appears for the first time.
This has only one link with the keyword "science fiction". However, the keyword "education" does not have a direct link with the pivotal term "popular culture", but is located in the same spatial environment.
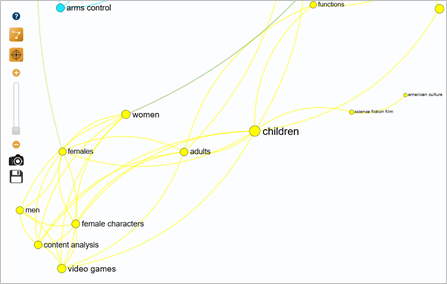
Finally, the yellow cluster focuses on the identity of the protagonists and their staging (film, book and video games). In relation to the initial topic, it would be interesting to refine the next query with a keyword on the target audience, such as "children", to reveal points of connection with the red cluster.
This initial broad exploration enables us to delimit the themes of the research topic and identify new types of keywords to refine the initial search.
# Explore databases
## ISTEX search engine (multidisciplinary)
Use of the ISTEX demonstrator (www.demo.istex.fr), an educational tool for building computer queries, to refine the initial query.
Creation of new queries/maps to interpret the new relationships between the keywords identified on the first map in three different clusters: "popular culture", "learning" and "children".
QUERY N°2
"Star Wars" AND "popular culture" AND (abstract:*)
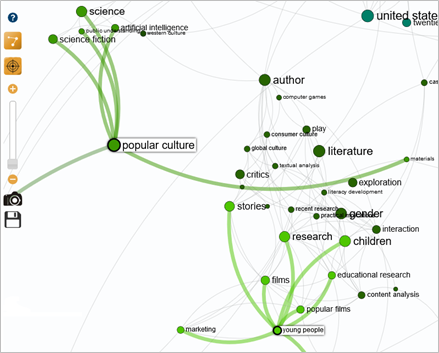
The second query investigates the spatialization and connections of keywords linking "Star Wars" to "popular culture". The aim is to find direct links or to identify keywords in common that could link them together.
The three keywords identified on the previous map are spatially close. The word "educational research" is closest to "learning", and links up with "popular culture", "children" and "young people".
To link them directly, we need to specify the search query once again. We prefer to target "young people" rather than "children" to direct the link to the "popular film" repository.
REQUEST N°3
"Star Wars" AND "popular culture" AND "young people" AND (abstract:*) AND qualityIndicators.pdfWordCount:[500 TO *]
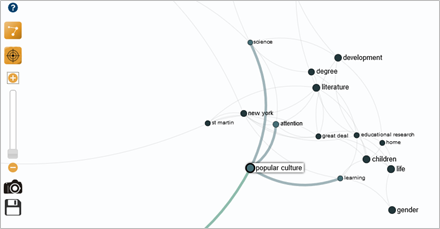
The third query reveals a particularly interesting result, as it brings together pivotal terms and identified keywords within the same cluster. The word "popular culture" is directly linked to "learning", which in turn is linked to "children" and "educational research".
The two new queries are interesting and usable. The next step is to test them on other databases and gradually complete a CSV spreadsheet like a "logbook".
## Isidore search engine (SHS)
The chosen subject is more a SHS theme. The first reflex is to use TGIR Huma-Num's Isidore search engine, which brings together results from several SHS databases.
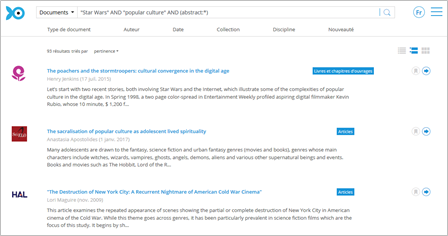
A query on Isidore returns 93 results, spread across a number of platforms such as OpenEdition, Scielo, HAL, Thèse.fr, etc.
By exploring the resources listed in Isidore in greater detail, we can carry out an initial filter to retain publications of interest, since the selection is not yet complete.
# Import a spreadsheet in CSV format
The spreadsheet will enable the operator to keep a logbook to develop his own corpus of data.
In fact, it is possible to use Gargantext's computing and processing power to analyze a corpus other than those proposed in the list of searchable databases. Then aggregate the results in the spreadsheet.
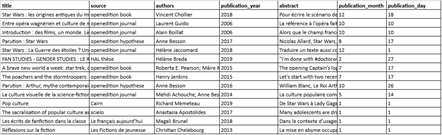
All you need to do is complete a spreadsheet based on the Gargantext corpus export model, with seven main columns (in any order):
* Column 1 "title": title of the publication
* Column 2 "abstract": publication summary
* Column 3 "authors": authors of the publication
* Column 4 "source": publisher or journal of the publication
* Column 5 "publication_year": year of publication
* Column 6 "publication_month": month of publication
* Column 7 "publication_day": day of publication
[Precise details of how to import CSV files can be found on this page](https://write.frame.gargantext.org/970190a1f295b48009a8bb1f850462851395794d9b28bd90fa218b0df5b4676c?view#)
## File formatting
The logbook in spreadsheet format can be edited on a Framacalc spreadsheet directly on the GarganText interface.
REQUEST N°2
"Star Wars" AND "popular culture" AND (abstract :*)
The spreadsheet must be converted to CSV format with the "comma-separated values" upload option.
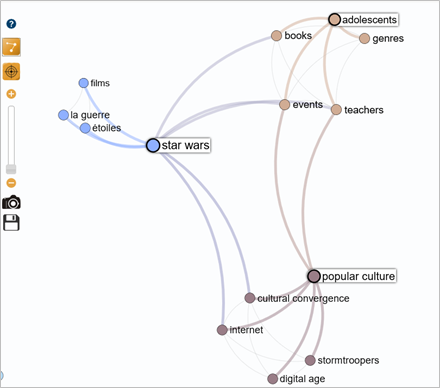
The map of the customized corpus in CSV format is very similar to that of query no. 2, carried out exclusively on ISTEX. The term "educational" has been replaced by "teachers". The appearance of the term "cultural convergence" is interesting for linking "Star Wars" to "popular culture" for further keyword research.
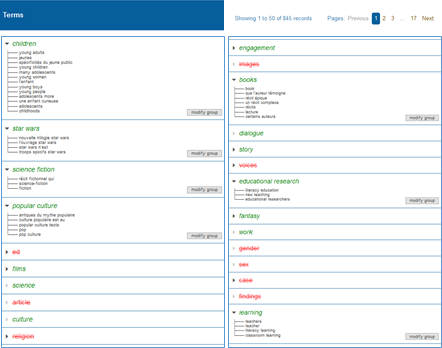
## List of terms
At this stage of the study, the term list work (category and grouping) is essential to orient the visualization towards a specific angle of the research subject. These terms are grouped according to the following model: validated (green), suggested (black), rejected (crossed-out red).
# Final map - conditional distance
The final map analyzes the "logbook" (personalized corpus), which includes the 15 results of the ISTEX search and 15 results of the Isidore search.
In this corpus, the pivotal terms and keywords "learning", "popular culture" and "young people" were distributed across three distinct clusters.
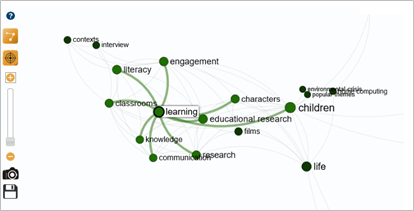
Cluster topology is built on a centralized model (graph theory), an architecture where all vertices are attached to a single pole.
This distribution is useful for identifying publications that are specifically linked to each keyword.
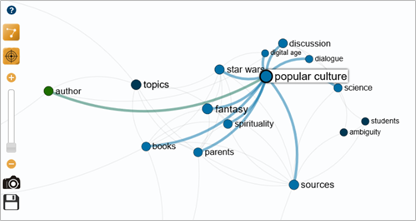
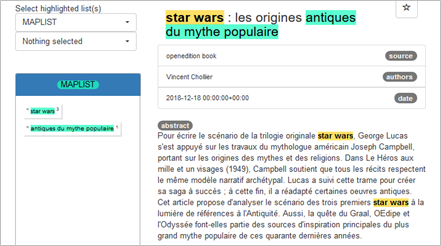
Depending on the link, you can browse publications by associating two terms such as "popular culture" and "star wars".
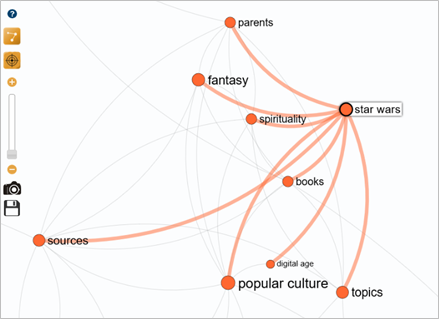
This link contains 8 scientific articles, such as Star Wars: The Origins of Popular Myth, which could be used as the basis for a section on the mythological inspiration of the Star Wars universe.
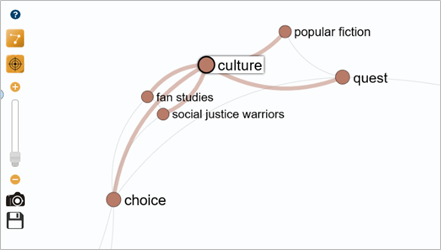
Finally, we note the emergence of a new cluster on culture, popular fiction and fan studies. It would be interesting to explore this cluster further to understand the involvement of fan communities in the transmission of popular culture.
# Conclusion
This study of the "influence of the Star Wars universe on modern popular culture among young people" led us to explore a number of databases, including ISTEX, HAL, OpenEdition, Cairn and Scielo.
An initial mapping exercise based on the ISTEX keyword search identified a number of terms to clarify the angle of the search: "learning", "educational research", "teachers", "children", "young people", "adolescent", "fan studies", etc.
This keyword exploration enabled us to establish new, more precise queries (targeting the angle of analysis) by combining several query conditions.
Once the query has been set, it is tested on several databases to build up a personalized corpus (logbook) within a spreadsheet. This document is then exported in CSV format for import into Gargantext.
The final map, divided into four clusters, reveals four main thematic sections, allowing key publications to be identified at each stage.
Here's an example of the breakdown of sections that could be developed to address the initial problem:
- Popular culture and ancient myths
- The influence of distribution media (books and films)
- Teaching and educational research practices among children and young people
- Fan studies on popular fiction and culture