# 🚤 1.1. Processus d’analyse de Gargantext
Gargantext est une solution logicielle en ligne pour la __production, l’exploration et l’annotation__ d’analyse de corpus bibliographiques.
> On entend par “corpus bibliographique” sur un sujet ou un thème donné, plusieurs centaines de références bibliographiques issues de bases de données scientifiques et techniques (telles que [Web of Knowledge](https://webofknowledge.com/) ou [Scopus](https://www.scopus.com/)), qu'il est impossible de traiter séquentiellement et manuellement.
>
<center>
</center>
Il s’adresse aussi bien aux enseignants-chercheurs, étudiants en enseignement supérieur et aux documentalistes, qu’aux veilleurs, spécialistes d'un domaine R&D ou économique, non nécessairement professionnels de la documentation ou de l'informatique, qui veulent sur un domaine de connaissance donné :
* avoir une __vue d'ensemble et une première approche__ du sujet de recherche,
* __suivre et analyser__ l'évolution thématique, identifier les relations intra et inter-thèmes non explicites,
* __repérer l'émergence__ de nouvelles technologies, de nouveaux thèmes de recherche,
* __identifier et regrouper__ les acteurs et leurs institutions par thèmes,
* __repérer les pôles d’excellence__ et évaluer le positionnement thématique d'acteurs, d'institutions ou de pays.
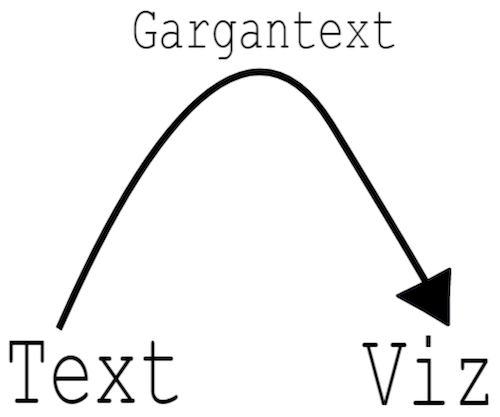
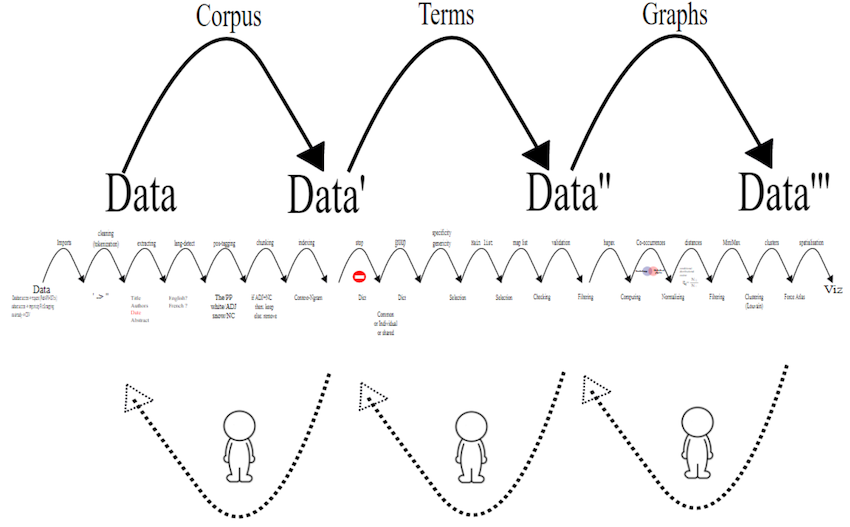
Avant de se lancer dans Gargantext, il est utile de comprendre les grandes lignes des traitements exécutés. Le processus de traitement de Gargantext passe par trois phases :
1. [Le nettoyage du corpus](https://write.frame.gargantext.org/s/74ccb14a280ea5097c04aaef07121365d015e03c596306e49d307010ff0f4a8d) au moyen de techniques avancées de text-mining et de traitement automatique du langage naturel,
2. __L’indexation et l’analyse des termes__ au moyen de techniques de datamining et de traitements statistiques,
3. __La représentation graphique et visuelle__ des données traitées obtenues.
<center>
[](https://dl.gargantext.org/workflow.svg)